ejabberd massive scalability: single node with 2+ million concurrent users

How Far Can You Push ejabberd?
From our experience, we all get the idea that ejabberd has massive scalability. However, we wanted to provide benchmark results and hard figures to demonstrate our outstanding performance level and give a baseline about what to expect in simple cases.
That’s how we ended up with the challenge of fitting a very large number of concurrent users on a single ejabberd node.
It turns out you can get very far with ejabberd.
Looking for experts to deploy an enterprise-grade ejabberd cluster?
Contact us now »
Scenario and Platforms
Here is our benchmark scenario: Target was to reach 2,000,000 concurrent users, each with 18 contacts on the roster and a session lasting around 1h. The scenario involves 2.2M registered users, so almost all contacts are online at the peak load. It means that presence packets were broadcast for those users, so there was some traffic as an addition to packets handling users connections and managing sessions. In that situation, the scenario produced 550 connections/second and thus 550 logins per second.
Database for authentication and roster storage was MySQL, running on the same node as ejabberd.
For the benchmark itself, we used Tsung, a tool dedicated to generating large loads to test servers performance. We used a single large instance to generate the load.
Both ejabberd and the test platform were running on Amazon EC2 instances. ejabberd was running on a single node of instance type m4.10xlarge (40 vCPU, 160 GiB). Tsung instance was identical.
Regarding ejabberd software itself, the test was made with ejabberd Community Server version 16.01. This is the standard open source version that is widely available and widely used across the world.
The connections were not using TLS to make sure we were focusing on testing ejabberd itself and not openSSL performance.
Code snippets and comments regarding the Tsung scenario are available for download: tsung_snippets.md
Overall Benchmark Results

We managed to surpass the target and we support more than 2 million concurrent users on a single ejabberd.
For XMPP servers, the main limitation to handle a massive number of online users is usually memory consumption. With proper tuning, we managed to handle the traffic with a memory footprint of 28KB per online user.
The 40 CPUs were almost evenly used, with the exception of the first core that was handling all the network interruptions. It was more loaded by the Operating System and thus less loaded by the Erlang VM.
In the process, we also optimized our XML parser, released now as Fast XML, a high-performance, memory efficient Expat-based Erlang and Elixir XML parser.
Detailed Results
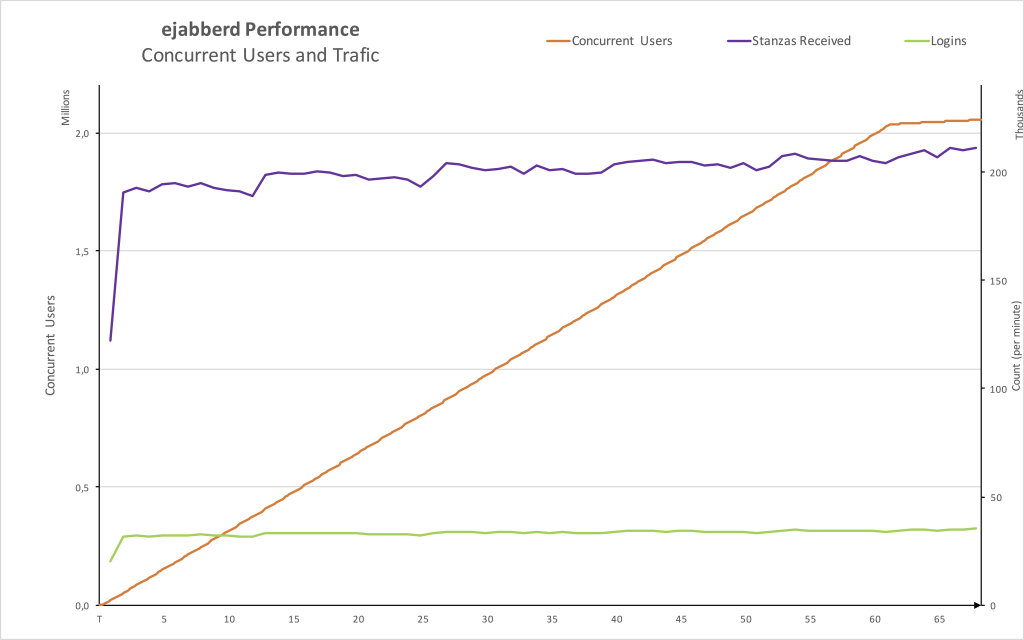
ejabberd Performance
Benchmark shows that we reached 2 million concurrent users after one hour. We were logging in about 33k users per minute, producing session traffic of a bit more than 210k XMPP packets per minute (this includes the stanzas to do the SASL authentication, binding, roster retrieval, etc). Maximum number of concurrent users is reached shortly after the 2 million concurrent users mark, by design in the scenario. At this point, we still connect new users but, as the first users start disconnecting, the number of concurrent users gets stable.
As we try to reproduce common client behavior we setup Tsung to send “keepalive pings” on the connections. Since each session sends one of such whitespace pings each minute, the number of such requests grows proportionately with the number of connected users. And while idle connections consume few resources on the server, it is important to note that in this scale they start to be noticeable. Once you have 2M users, you will be handling 33K/sec of such pings just from idle connections. They are not represented on the graphs, but are an important part of the real life traffic we were generating.
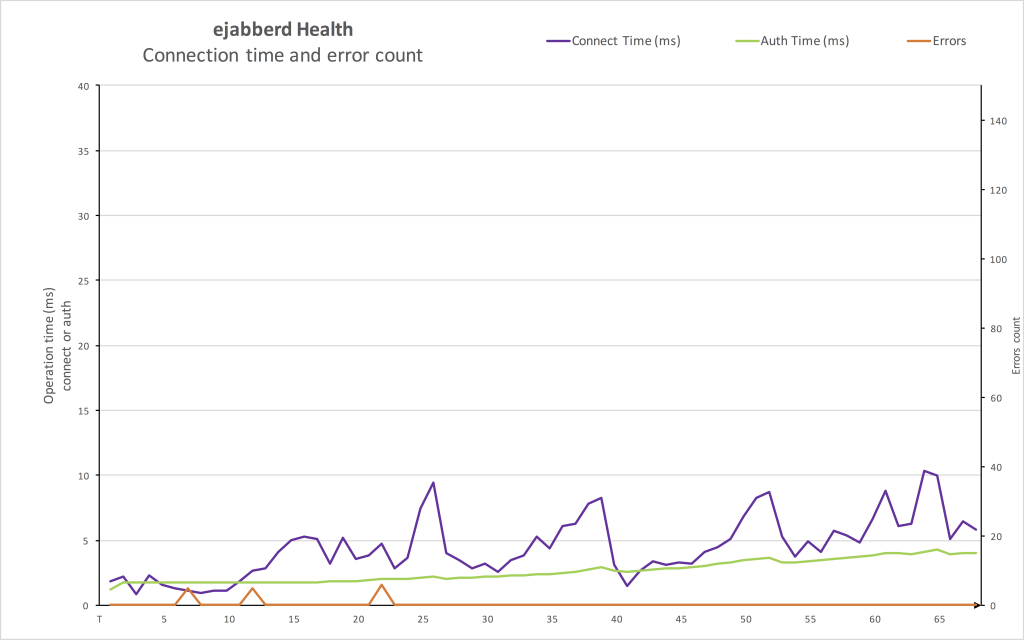
ejabberd Health
At all time, ejabberd health was fine. Typically, when ejabberd is overloaded, TCP connection establishment time and authentication tend to grow to an unacceptable level. In our case, both of those operations performed very fast during all bench, in under 10 milliseconds. There was almost no errors (the rare occurrences are artefacts of the benchmark process).
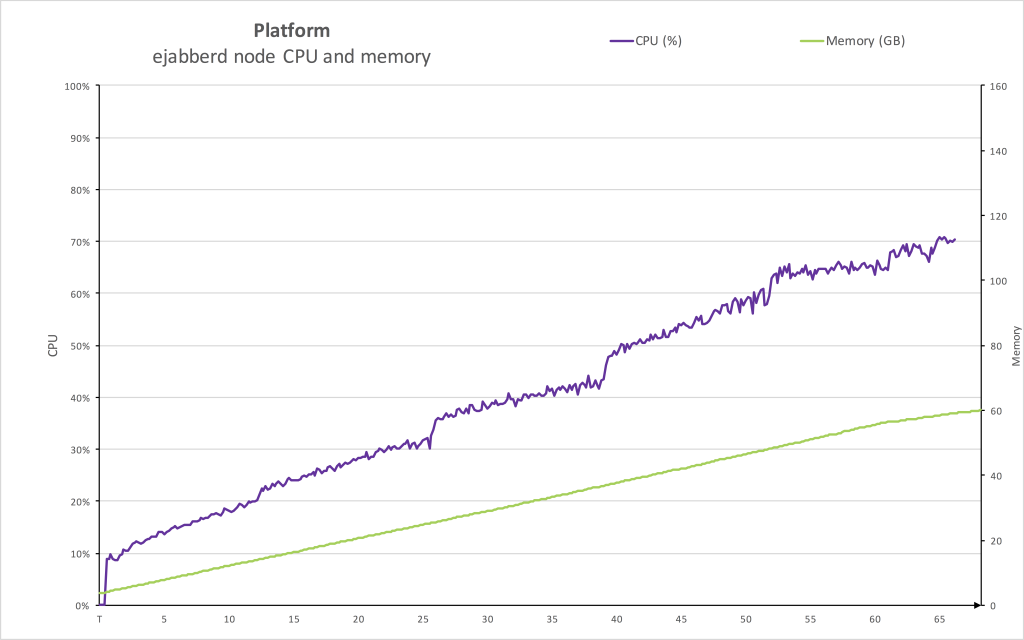
Platform Behavior
Good health and performance are confirmed by the state of the platform. CPU and memory consumption were totally under control, as shown in the graph. CPU consumption stays far from system limits. Memory grows proportionally to the number of concurrent users.
We also need to mention that values for CPUs are slightly overestimated as seen by the OS, as Erlang schedulers stay a bit of busy waiting when running out of work.
Challenge: The Hardest Part
The hardest part is definitely tuning the Linux system for ejabberd and for the benchmark tool, to overcome the default limitations. By default, Linux servers are not configured to allow you to handle, nor even generate, 2 million TCP sockets. It required quite a bit of network setup not to have problems with exhausted ports on the Tsung side.
On a similar topic, we worked with the Amazon server team, as we have been pushing the limits of their infrastructure like no one before. For example, we had to use a second Ethernet adapter with multiple IP addresses (2 x 15 IP, spread across 2 NICs). It also helped a lot to use latest Enhanced Networking drivers from Intel.
All in all, it was a very interesting process that helped make progress on Amazon Web Services by testing and tuning the platform itself.
What’s Next?
This benchmark was intended to demonstrate that ejabberd can scale to a large volume and serve as a baseline reference for more complex and full-featured platforms.
Next step is to keep on going with our benchmark and optimization iteration work. Our next target is to benchmark Multi-User Chat performance and Pubsub performance. The goal is to find the limits, optimize and demonstrate that massive internet scale can be done with these ejabberd components as well.
A Few Words on ejabberd Business Edition
ejabberd Business Edition did even better than ejabberd Community Server. The memory footprint was slightly lower overall (5%). However, if you consider that with eBE we kept a part of the data in memory, we did a lot better. We used P1DB instead of MySQL for rosters and authentication storage. P1DB is a database developed by ProcessOne. It is designed especially for ejabberd to meet the needs of large cluster distribution and replication. It includes a mix of memory storage, fast disk mapping and built-in data replication across ejabberd nodes. P1DB is built into ejabberd Business Edition.
Join Us at Advanced Erlang ejabberd Workshop
Next ejabberd workshop organized by Advanced Erlang Initiative takes place on January 26th in Krakow. Let’s meet there!

{kind=link}
{kind=link}
{kind=link}